Toen ik me gisteren na de lunch wilde voorbereiden op mijn volgende vergadering, merkte ik dat ik geen toegang had tot mijn e-mail. Mijn Microsoft Teams-client kon geen verbinding maken met de buitenwereld en het duurde een eeuwigheid voordat websites waren geladen. Slechts een paar minuten later meldde onze IT-afdeling dat er sprake was van een intern probleem met de uptime bij onze datacenter-provider. Onze servers in het datacenter waren nog allemaal in de lucht, maar we konden er geen toegang toe krijgen. Al snel kwam de aap uit de mouw: een DDoS-aanval had het netwerk van de provider grotendeels platgelegd.

Uptime (van systemen) ≠ beschikbaarheid (van diensten)
Na ongeveer drie uur downtime, kregen we weer toegang tot onze digitale bedrijfsbronnen. Het percentage van de uptime voor de IT-infrastructuur, een belangrijke KPI voor veel bedrijven en IT-afdelingen, was door de storing onveranderd gebleven, maar de beschikbaarheid van applicaties en diensten had wel onder dit incident te lijden. Dit roept de nodige vragen op: wat is uptime, wat is beschikbaarheid, en hoe verschillen ze van elkaar? Uptime is een maatstaf voor de betrouwbaarheid van systemen en wordt uitgedrukt in een percentage van de tijd dat een machine (meestal een computer) functioneel en beschikbaar is geweest (bron: Wikipedia). Uptime houdt in dat een systeem gebruiksklaar is, maar het betekent niet per definitie dat alle benodigde applicaties en diensten beschikbaar zijn, of dat een netwerkservice beschikbaar is en in de verwachte bandbreedte voorziet. De beschikbaarheid verwijst naar de waarschijnlijkheid dat een systeem tijdens het uitvoeren van een taak naar behoren zal functioneren (bron: opnieuw Wikipedia). Als we naar de productieomgeving kijken, kan het verschil tussen uptime en beschikbaarheid het beste worden vergeleken met de OEE (Overall Equipment Effectiveness) en TEEP (Total Effective Equipment Performance). Deze maatstaven houden rekening met alle gebeurtenissen die de productieomgeving platleggen.
De vijf negens
U hebt vast wel eens gehoord van de ‘vijf negens’. Deze term verwijst naar een uptime- of beschikbaarheidspercentage van 99,999%. Hoewel vijf negens de meest optimale situatie vertegenwoordigen (naast de heilige graal van 100%), heeft dit concept ook betrekking op een beschikbaarheidspercentage met minder negens. En daarmee zijn we aangekomen bij de ‘Tabel van Negens’:
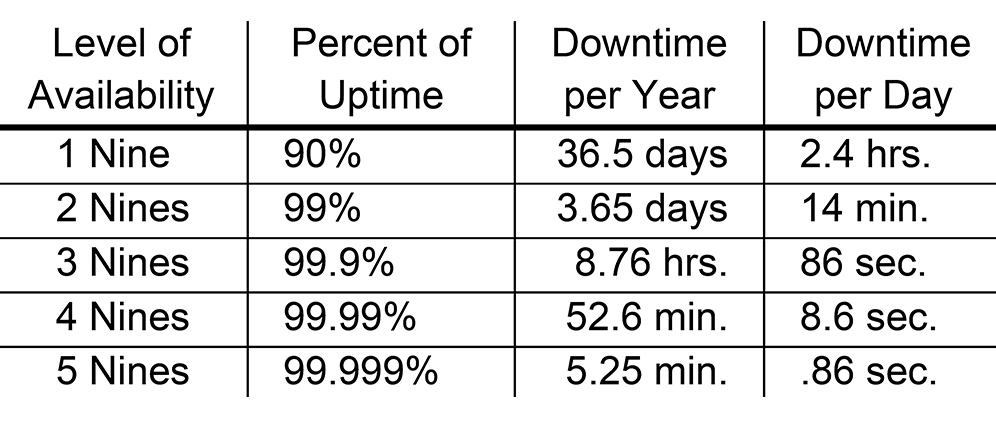 Het aantal negens wordt vastgelegd in een overeenkomst met de dienstverlener (de Service Level Agreement, SLA). Hoe meer negens de SLA garandeert, des te hoger het prijskaartje van de dienst.
Het aantal negens wordt vastgelegd in een overeenkomst met de dienstverlener (de Service Level Agreement, SLA). Hoe meer negens de SLA garandeert, des te hoger het prijskaartje van de dienst.
‘100% uptime is tegenwoordig niet langer relevant’
Dit soort statements hoor je tegenwoordig steeds vaker. Ze zijn niet afkomstig van beheerders of datacenter-exploitanten, maar van applicatiebeheerders. In deze tijd van high availability, gedistribueerde systemen en containeroplossingen is een applicatiebeheerder niet langer afhankelijk van één specifieke hardwarevoorziening. Veel belangrijker is dat de dienst zelf, oftewel het verbonden bedrijfsproces, te allen tijde beschikbaar en operationeel is.
De heilige graal van 100% uptime is en blijft onbereikbaar. Dankzij de ondersteuning van allerhande high availability-oplossingen kan een applicatie beschikbaar blijven tijdens een hardwareupgrade, omdat die dynamisch en zonder onderbreking naar een ander hardwaresysteem kan worden overgezet. De fysieke component moet echter opnieuw worden opgestart, en dat resulteert onvermijdelijk in downtime (en daarmee minder dan 100% uptime).
Gevolgen voor de bewaking van de IT-omgeving
Naast de bewaking van hardware en componenten wordt de bewaking van complexe, onderling afhankelijke bedrijfsprocessen met de dag belangrijker. De beheerder van een e-mailsysteem hoeft niet langer te weten hoeveel megabytes aan RAM een hardwaresysteem benut. Voor die beheerder is het veel interessanter om te weten of de mailboxen beschikbaar zijn, of clients de server snel genoeg kunnen benaderen, of de POP- en SMTP-diensten naar behoren functioneren en of er sprake is van een stabiele verbinding met Active Directory. Dit vraagt om een duidelijke definitie van serviceprocessen en een zo grondig mogelijke afspiegeling daarvan binnen de bewakingsomgeving.
Neem bestaande SLA’s onder de loep
Voor 2019 raad ik dan ook het volgende goede voornemen aan: check de SLA’s van bijvoorbeeld datacenter- of webhosting-providers en hun definitie van uptime. Veel dienstverleners beperken hun uptimegarantie tot de beschikbaarheid van hardwaresystemen. De beschikbaarheid van services en processen wordt daarmee buiten beschouwing gelaten. Ik kan me voorstellen dat overeenkomsten op dit punt ruimte voor verbetering bieden. Praat met leveranciers en dring de risico’s op alle fronten terug!